Today we released version 0.1 of the Ocelot software (two days early!). 0.1 provides the foundation for Ocelot, and doesn't yet have any system model-specific code. You can see the features that were resolved in the 0.1 milestone here.
The foundation in code
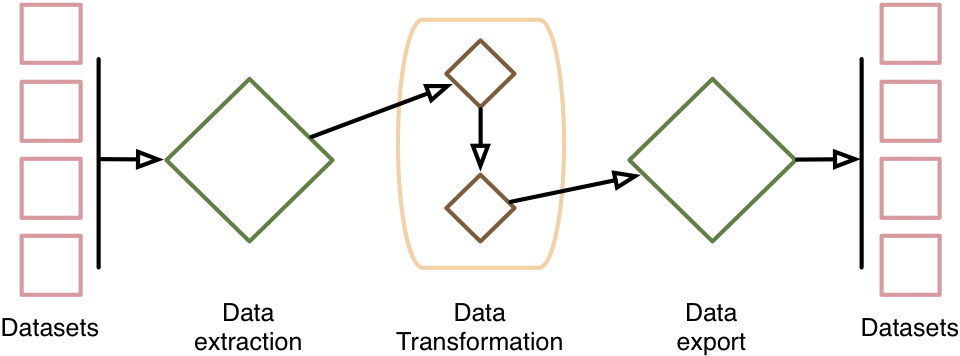
The building blocks for Ocelot are explained in detail in the documentation. The basic workflow is:
- Extract data from ecospold2 files to the internal dataset format.
- Read user input to define a system model as a list of Python functions.
- Start a logger, and create an output directory.
- Apply the system model transformation functions to the extracted data, saving the database at each step, and logging changes.
- Save the final database.
- Parse the logfile and generate an HTML report.
All these building blocks are included in 0.1 - system_model, generic_extractor, Logger, HTMLReport, etc. You can even see an example Ocelot run report. Bear in mind that we mostly have example transformation functions so far, so the example report is not so impressive. It is also not beautiful - if you have JS/CSS skills and want to contribute, please let us know!
Testing
Testing, and the documentation of test cases and expectations, are a core component of Ocelot. Our tests currently cover foundational code, such as the extraction of ecospold2 data and running transformation functions. We test locally during development, but also have continuous integrations services testing on Windows and Linux every time a commit is published to Github. We even have automated test coverage data generated as well.
Future development
Our development for the next few months is defined in the milestones. Each milestone is defined by a number of tasks (issues), and the milestone is reach when all relevant issues are closed. In this way, we are hoping to make the development, priorities, and future plans for Ocelot as transparent as possible. For all development going forward, we will try to follow the Github suggested workflow, with named branches and pull requests. In this way, each addition will come self-contained with documentation and tests, as well as a discussion of its flaws and merits. We have also created wiki pages for system model variations and ideas for Ocelot desired capabilities - please add your input here!
This post is guest written by Brandon Kuczenski, a researcher at UCSB, and chair of a SETAC NA working group of Inventory Model Description and Revision. Brandon has engaged the Ocelot team in the comments section of the development blog, and we are grateful that he has accepted our offer to explain his thoughts in a better forum.
Inventory Linking Software
Chris asked me to write a guest post (and possibly a series of posts) since I am very opinionated about LCA software, and I happily agreed. As it happens, I've been working some years in my own windowless room on an LCA computation suite that takes a radically different approach from what is out there now. For a number of reasons (mainly the choice of language and development environment), the products of that project are not easily extendable, and for reasons having to do with my own technical limitations, they would not scale up well to a project the size of Ecoinvent. So I am working on a re-implementation (in python). But in part because of my radically different approach, I have a different notion for what a "linker" is good for and how it would work. In this post I will explain my motivations, and outline a few design principles that stem from them. It may turn out that the software I have in mind fills a different niche from what the Ocelot team has in mind for Ocelot.
Where did this number come from?
First off, I am more interested in LCA studies than LCI databases. I am primarily concerned with the review and validation of LCA results. When I see a publication that reports the global warming potential (GWP) of a product, I want to know how the authors arrived at the reported value. I don't care so much about being able to perform uncertainty analysis or monte carlo simulation -- I want to understand the model. A few days ago, in a fairly defensive line of comment on the Thinkstep LinkedIn community, Christoph Koffler commented that "the Critical Review of LCA studies can include a model review, but it doesn't have to" (link restricted to group members). To me, that statement is patently absurd. If you are not reviewing the model, you are essentially reviewing a marketing document. Maybe what he meant as a GaBi person was, you don't have to see the GaBi model itself. With that I agree -- but you need to look at some representation of the model.
The problem is that LCA practitioners don't really have a precise way of describing models. We write reports, and these reports can run to hundreds of pages, but often the "model" is just shown as a box diagram -- literally, a picture -- and every author's picture is drawn differently and includes and excludes different things. The diagram is then explained with written text that may or may not be intelligible to a reader.
Pondering this led me to two realizations:
- A model's structure can be described without including any data. The model itself is a set of boxes and arrows, also known as a directed graph. We know how to describe directed graphs precisely.
- The model's structure makes reference to a lot of pre-existing data. Almost every model uses background data that comes from an externally-maintained database, be it Ecoinvent, GaBi, or whatever. The set of background data sets used is finite and typically very small. In describing a model, it is sufficient to list those datasets in an unambiguous way. A reviewer can then look up the data sets in your list, retrieve them, and check them and even replicate the background of your model if desired.
At this point, it is clear that there are different concepts of "linking" involved. One, the one that Ocelot is ostensibly concerned with, is used in the preparation of background databases, like ecoinvent. The other, that my research is concerned with, is used in connecting background datasets with foreground models. The first kind is done by the database maintainer. The second kind is done by the study author. I don't believe they should be confused (and I confess I may have confused them in my critical comments on last week's post).
Design Principles for Linking
Taking now the perspective of "linking" as two distinct tasks, or more accurately as an iterative task over successively larger scopes, I can offer some principles that I feel should inform the design of a linking tool. Some of them are deliberately contrary to Ecoinvent's (and also Thinkstep's) way of doing things, since I like to be provocative. They are all grounded in the needs of the study author, and thus become mandates to the data designer.
- Flows are Things. A process is nothing without its flows. But flows themselves exist without processes! Flows are observable, measurable, extensive- which processes are not. Balancing flows is the basis for LCA accounting. The linker data model should recognize flows as first-class entities. In fact, a flows-first data model may be more intuitive for the user of LCA software than the current, dominant process-first view.
- Multiple Databases. A study author is not going to want to be constrained to using one database, and the reason is that no single database can cover the Earth: there is too much knowledge required. It is hubris to think otherwise. Proof of this is in the fact that the 2014 GaBi professional database has 2,600-odd processes, and over 600 of them have "Steam (MJ)" as the reference output (another 230 output "Thermal Energy"). Granted, there are a lot of ways to make steam -- a lot of technologies, a lot of places -- but this is exactly why no single database provider should pretend it can cover everything. The linker should take this into account and should be prepared to use data from multiple providers.
- The accounts don't have to balance. This goes all the way back to Heijungs, who in his epic thesis "Economic Drama and the Environmental Stage" formulated LCA as analogous to a system of national accounts, thereby fixing allocation as the fundamental problem in LCI database construction. But this is a myth: it was a simplification for Leontief and it's flat-out false for LCA, because unused products routinely enter export markets, stockpiles, or find alternative uses, and those are typically outside the system boundary. Steam gets vented. Wouldn't it be more edifying if, rather than pretending a refinery's outputs are uniform and allocatable, one output of an LCA computation is the quantity of residual oil that has to be sloughed off to other markets in the process of making your product? Then it could be left to the user how to allocate the burdens. Such a system is easily achievable.
- [Partially] Aggregate By Reference. The design of certain tools (OpenLCA in particular, but possibly others) requires a user to load the entire ecoinvent database, in unit processes, in order to perform computations. But most of the time this isn't necessary. First, the core database has presumably been reviewed by experts, and since processes are all interdependent, the internal ones should not be changed by the user AT ALL. Second, the amount of redundant computation is tremendous. Ecoinvent has already done all the aggregations for all the processes in all its system models. Those numbers shouldn't change, so why re-compute them? Finally, this approach precludes using multiple system models at once, or at least doing so causes OpenLCA to place a tremendous demand on my poor laptop.
All of the above means there is essentially no reason to force users to load the whole database in bulk. Instead, users should build models by reference to upstream and downstream components that are computed at the database level. If desired, they can be free to adapt unit processes into their own foregrounds, in the spirit of Bourgault et al 2012, and these they can modify freely. The unit processes already include their own references to fixed database content. Moreover, the reference data sets don't have to be fully aggregated -- they could be partially aggregated in accordance with principles #2 and #3. Obviously the nature of these components is yet to be determined.
What kind of tool could possibly satisfy these principles? Well, one thing is for sure: the tool could not be run until after an LCA study model has been constructed. The database linker would necessarily finish with incomplete pieces, and these pieces would later get connected when the linking tool is run by the data end-user. The system implied by these principles is necessarily distributed across multiple data providers. Thus it's wholly speculative, and also somewhat incompatible with currently available data resources. But this post is all about radical re-imagining.
I have removed comments from the front page, because for silly technical reasons that got attached to whatever the latest blog post, making for a disjointed conversation. However, I didn't want to lose what had already been said, so here is are the comments so far between Brandon Kuczenski and the Ocelot project team.
Brandon Kuczenski
It seems to me that if you are already starting with ecospold v2 and ending with ecospold v2, you have already foreclosed a great many design decisions / discussions.
Chris Mutel
One some level, you are completely correct - ecospold 2 builds in a certain set of assumptions, both explicit and implicit, and these assumptions impose limits. I don't think any of the actual code aside from IO will include anything ecospold 2-specific, but there will be an internal data format which will mirror ecospold 2 in many ways.
One of the explicit principles in the Ocelot grant was to "not let the best be the enemy of the good", and we think it is better to get at least some system model principles in place as tested, open source computer code, than to wait for the perfect data format. There are also some practical reasons for choosing ecospold 2 - you can add arbitrary properties, so it is quite flexible, and it supports parameterization. Most importantly, ecoinvent is the only LCI database that I know of that provides "raw" master data where no system models have been applied at all, and ecoinvent is provided in ecospold 2.
Certainly our work will only be the first step on a longer conversation with the community, and I would be quite curious to hear about specific examples of what you think would be ignored or overseen.
Brandon Kuczenski
In my opinion the lack of a "flow" as a standalone entity is a serious shortcoming in a linking algorithm, since flows are the things that link. But my bigger concern is the philosophical one that is implied in squeezing everything into a data format that is so very expensive to work with- and in doing so a priori, before the design principles of the task are even established (or at least known to others).
I consider "arbitrary extensibility" to be a weakness of ecospold, not a strength. I've long thought it a folly for ecoinvent to try to fold all their complex data (transformations! LCIA methods! markets! inheritance! uncertainty! parameters!) into a single data object that nobody but ecoinvent knows how to author or read. ILCD, verbose as it is, at least has some concept of separation of concerns. (ILCD also does not do many of the things ecoinvent requires-) I have a genuine fear, especially reading your response, that ocelot is just a trip further down a rabbit hole that is already (from the outside) too deep to enter.
It's also not true that ecoinvent provides "raw" master data to its users! The file list only has linked system models. They're also not on nexus.openlca.org. It's true that I can view the unlinked data on the website, one data set at a time, via search, but that's not the same thing.
n.b. US LCI, on the other hand, is made up of "raw" unallocated multioutput processes.
Anyway, forgetting the input format- why would the output format be ecospold 2?
There are very few people who would consider a set of 11,000 XML files to be a useful thing they would want to generate. If the object of the algorithm is to create a square technology matrix, why make the output so very, very far from that? Why not deliver, say, a technology matrix? It would be 0.1% the size, it would be easy to interpret, it would be software independent.
A bit later
All this is just to say, it sounds like ocelot is mainly going to be useful for internal ecoinvent personnel. Which is not a bad thing! I think it's great that ecoinvent will be able to do new and exciting things with system models. It's just- a smaller community than I thought you meant at first... and to say it in a nasty way, because I have a chip on my shoulder.
Chris Mutel
Brandon makes some interesting points, and I have invited him to make a guest blog post about what he imagines a project like Ocelot could become. So I postpone discussion of broader theory questions for now. However, I do have to disagree with a few technical points.
First, ecospold 2 definitely has "flows" distinct from activities. For example, the complete list of flows in ecoinvent 3.2 is included in the files Content/MasterData/IntermediateExchanges.xml and Content/MasterData/ElementaryExchanges.xml, both available here.
Next, while it is true that unallocated data is not available on nexus.openlca.org (an unaffiliated website), you can get all the master data by just asking the ecoinvent team. They don't bite.
It is also a bit of an exaggeration to state that "nobody but ecoinvent knows how to author or read" ecospold 2. For example, you can find open source importers and converters for Java and Python. In my personal opinion, Ecospold 2 is sometimes a pain, but it is not such a dramatic pain. For what it's worth, I have given multiple presentations about how I really want the JSON linked data schema to take over the world.
It is worth briefly mentioning that the US LCI is not raw data - it is linked data, resolved in time and space. System models are much more than just allocation.
Finally, here is a kitten:
Guillaume Bourgault
Chris has already said most of what I wanted to say, I'll just add a few words.
The schema for the master data files is available for these files, upon request. I'm happy to answer all questions about these files. The schema for the dataset ecospold2 format is also available.
About the output format: all the existing software who deal with the ecospold2 format have the capacity to take those files and transform them into a matrix. We also have the internal tools to transform ecospold2 files to a matrix representation, both in Python scipy.sparse matrices and in machine-readable txt format that can be reconstituted into a matrix easily.
We think it is important to use ecospold2 format as an output because it carries with it all the relevant meta information necessary to understand the datasets. We plan to add comments, where necessary, along the calculation chain, when it will be judged necessary (for example, allocation, loss, market group replacement, geography linking, etc.)
That being said, more than one output is for from impossible, and since we already have some internal tools, we could easily include them as some "end-of-pipe" scripts for user comfort. We also care about the accessibility of results. We are happy that you have suggestions about this aspect!
If I can provide the perspective of somebody answering support questions from the entire user base of ecoinvent. Brandon is right to point out that the ocelot project is "directly useful" to a very small proportion of users. The vast majority of our users do not care much about what we are discussing here. And if I can speak candidly, I am sometimes appalled by questions showing lack of understanding of vary basic LCA concepts from our users. At the other side of the spectrum, there is only a handful of people in the world who have the resources, interest and skills to actively contribute to the project. However, the entirety of the users will benefit indirectly from the fruits of this project, for example by the reassurance that system model assumptions have been thoroughly tested.
The purpose of the development blog is to allow open discussion about the kind of concerns Brandon has. The project is young enough to be steer in many directions. As somebody who usually focuses on computational aspects that most member of the community don't even want to think about, I'm quite happy to see Brandon's interest in the project. We obviously have to find a balance between the ideals we hold and what we can reasonably achieve with the resources we have for this project. As Chris pointed, not letting the best be the enemy of the good is something to keep in mind. The release of version 3.0 has been delayed because this principle was forgotten, and we are dealing with many legacy problems caused by this lack of foresight. Ocelot is the best initiative we have had so far to fix these legacy problems.
Well, this is a bit embarrassing. It turns out that I wrote a blog post almost exactly two years ago proposing essentially the Ocelot project, and then forgot about it. Brandon Kuczenski has been having a discussion with myself and others over the limitations that the ecospold 2 mental model brings in the comments of this development blog, and I was looking for historical examples of when I had complained about ecospold XML to show that I felt his pain, when I stumbled across this blog post, called "Some ideas on an open source version of the ecoinvent software."
I include below what I wrote in April 2014. It is exciting (and a bit scary) to be a part of the team trying to make "a brighter future"!
Ecoinvent version 3: A difficult elevator pitch
There are still a lot of people confused or doubtful about ecoinvent version 3. One of the big questions that people have, as seen repeatedly on the LCA mailing list, is exactly how ecoinvent 3 works. True, there is a document called the "data quality guidelines", which explains the concepts behind ecoinvent 3 in some detail. But even in the "Advanced LCA" PhD seminar that I led last fall, the data quality guidelines raised as many questions as it answered, and few have the days needed to read through that document thoroughly. The large number of changes from version two to version three, plus the fact that some LCIA results have changed a lot, leads many to doubt whether they should make the transition.
From my perspective, as someone who has played around with LCA software, the fact that the ecoinvent software is not publicly accessible is also a source of concern - especially ironic given the motto of the ecoinvent centre, to "trust in transparency." There were a lot of clarifications and modifications needed to turn the ideas of the data quality guidelines into working computer code, and these adaptations are just as important as the general data quality guidelines framework. It is my understanding that the ecoinvent centre is in the process of creating a new document that will more precisely give the rules for the application of the various system models, but this document is not yet finished.
One big step towards addressing these problems would be to have an open source version of the software that takes unit process master data sets and applies the different system models. If done properly, this software could provide a practical implementation of the abstract idea in the data quality guidelines, giving precise details on each step needed to get to the technosphere and biosphere matrices. In the rest of this post, I will give my thoughts on what such a software could look like.
Guiding principles
The first guiding principle of any such software must be practicality. Even a simple piece of software is a lot of work, and ecoinvent 3 would not be a simple piece of software. Therefore, the software should have limited scope - not all of the ecoinvent software functionality is needed - and should not reinvent the wheel, but build on existing libraries as much as possible. One should start with the easiest problems, and build up a set of simplified components that can handle most unit processes. Practicality also means using a well-established, boring technology stack.
The second guiding principle should be accessibility. The inspiration behind literate programming should apply here as well - the point of such a software is not just to redo work already done, but to make the rules, algorithms, and special cases understandable to people from different backgrounds. The documentation for backbone is a beautiful example of annotated source code, but probably using something like Sphinx, e.g. brightway2 documentation is a better example, as numerous diagrams and even animations may be necessary. Development should be open, and source code should be hosted on a service like github or bitbucket.
Of course, the cooperation of the ecoinvent centre would be critical for the success of any such effort. There are good arguments for having software development happen independent of ecoinvent, but probably the best approach would be to have a diverse team of people from inside and outside the ecoinvent centre.
Software components
The first major component is a data converter, to convert from the ecospold 2 XML format to something more easily accessed and manipulated. XML is a great format for inventory dataset exchange, as it has schema descriptions, validation, etc. but XML is not a great format for working with data. Just google for XML and awful or horrible or terrible or sucks. Anyway, the converter would transform the necessary parts of the unit process datasets to the native data structures of whatever programming language is chosen.
The second major component, and the hardest one, is the allocator. This would take as an input an inheritance tree of unit process data sets, and resolve each into an allocated, single output unit process (A-SOUP, terminology by Gabor Doka), whose output is a product located in time and space. This can start simple - just work on economic or mass allocation, or just substitution. In theory, or in a world where no one had invented allocation at the point of substitution, this could be trivially parallelized, and so should be relatively quick. At the beginning, the software doesn't need to do everything, and difficult data sets like clinker production could just be skipped for now.
The last big component is the linker, which matches demand for products to the A-SOUPs that produce those products in the correct time and space. I think that this should be relatively easy to do. One improvement over the procedure as illustrated in the data quality guidelines could be to define all geographic relations in advance, even in something as simple as a text file, to avoid having to integrate GIS functionality into the new software (see also Some thoughts on Ecoinvent geographies).
I envision the final codebase to have more tests than actual code, and significantly more documentation than actual code.
A brighter future
My best guess is that such a software would take around one year of work. The hard stuff has already been done by ifu hamburg and the ecoinvent centre. However, translating the work that has already been done into open source code will depend on a detailed specification document explaining exactly what the current software does.
If such a software were to come into existence, it could significantly help the adoption of ecoinvent version 3. It could also provide a nice foundation for future work. One of the very nice properties of the master unit process datasets is that one can develop new system models. A well-documented and well-tested open source software would allow both ecoinvent and others to develop new system models, and realize the promise of ecoinvent version 3.
There have been a number of good questions asked since we announced the Ocelot project on the LCA discussion list. As most of these questions were asked by private email, we are making an initial FAQ post, to be updated over time.
Is Ocelot LCA software?
No.
What is the output of a linking algorithm?
The input to a linking algorithm is set of datasets that are not yet finalized. For example, dataset A could need peanut butter as an input, and dataset B could produce peanut butter, but there would be no explicit link between A and B. Each transformation function will produce a new version of the set of datasets with one small change. In our example, the output of the transformation function would be a link from process B in process A. The output of a system model as a whole is a set of datasets that are completely linked and which produce a square technosphere matrix, i.e. a set of files you could import into LCA software.
Will a system model created with ocelot require ocelot to interpret?
No, the outcome of the system model will be a set of ecospold2 XML files, just like you can download right now for the three different system model versions of ecoinvent. These files will then be imported by other software such as Brightway2.
Functional programming is a style of programming characterized by first-class functions and the avoidance of mutable state. Ocelot will be written in Python, and functional programming is well supported in Python and its libraries. This blog post explains what functional programming means in the context of Ocelot.
Ocelot will ultimately have a pretty simple structure - data will be extracted by a data extraction class, and converted from the spold2 XML format to native Python data structures. Then, a series of transformation functions will be sequentially applied. These transformation functions each represent a choice in the system model. For example, determining the marginal producer in a market based on technology levels and political constraints would be a transformation function, and a new version of the data will be created where the marginal provider is labeled. Finally, the data will be converted from Python back to the spold2 XML format.
In Ocelot, each transformation will be a callable function or class that will take one argument - all datasets - and return all datasets. The actual data will not be changed, as it will be immutable; rather, a new version of the data will be created at each transformation step. The functioning of each transformation process can change depending on the system model configuration, and if any such configuration information is required the function will be curried ahead of time. It is also possible that multiple dispatch will be used to handle the same function in different system model contexts. Ideally, the main system model algorithm will be as simple as:
for function in prepared_and_ordered_functions:
data = function(data)
What does this programming paradigm bring to the table? There are several advantages.
First, and most importantly, each transforming function will a small and self-contained section of code, making it easy to understand and test. Functional programming, if done correctly, should have no side-effects, so each function can be independently tested. Ensuring consistent and error-free applications of system models is one of the design goals of Ocelot, and this separation of concerns will help us achieve that goal. An idealized transformation function will look like this:
def transformation_function(data):
new_data = [do_something(dataset) for dataset in data]
The lack of side effects or mutable state can also be a big help when dealing with complicated system modeling options. Those of you who have read through the data quality guidelines know that some system rules can include a complex set of interdependencies. For example, the long-term consequential model uses technology rules to choose the marginal producer of a technosphere flow, but only after excluding certain technologies due to political restrictions. We intend to split this if statement into two separate functions - one of which will remove technologies which are politically limited, and another which will choose the most modern among the remaining technologies. In addition to getting working versions of each system model choice in computer code, this division can really help everyone better understand exactly what, when, and how the different system models function.
In theory, the use of immutable data structures and transforming functions will also make it easy to parallelize the application of the system models. We will test whether there are benefits in the real world - libraries like multiprocessing or scoop still require serialization of data structures, which might negate the speed benefits of distributed processing.
Finally, logging the changes in each transforming step can make it easy to backtrack calculations and locate errors when they occur. This logging is against the strict interpretation of functional programming, as logs are a change in state, or a side effect of a function, but most rules need to be broken every now and then. Logging the data at each step can also make it possible to only run certain parts of the transformation chain, starting from the last known good data.