Functional programming & Ocelot
Functional programming is a style of programming characterized by first-class functions and the avoidance of mutable state. Ocelot will be written in Python, and functional programming is well supported in Python and its libraries. This blog post explains what functional programming means in the context of Ocelot.
Ocelot will ultimately have a pretty simple structure - data will be extracted by a data extraction class, and converted from the spold2 XML format to native Python data structures. Then, a series of transformation functions will be sequentially applied. These transformation functions each represent a choice in the system model. For example, determining the marginal producer in a market based on technology levels and political constraints would be a transformation function, and a new version of the data will be created where the marginal provider is labeled. Finally, the data will be converted from Python back to the spold2 XML format.
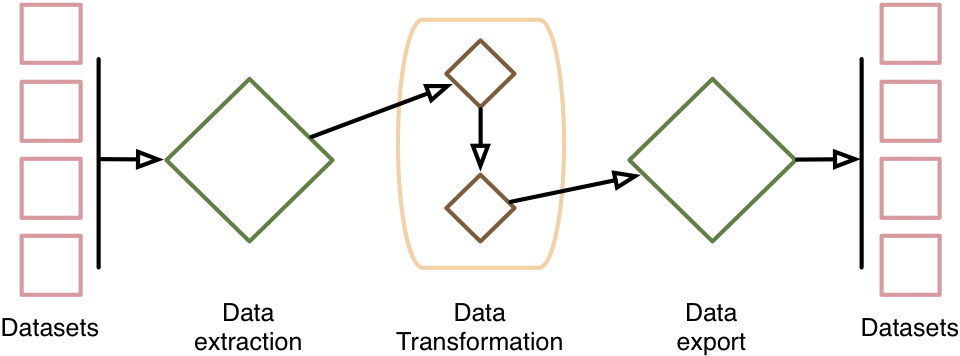
Figure 1: Flow logic of Ocelot data processing.
In Ocelot, each transformation will be a callable function or class that will take one argument - all datasets - and return all datasets. The actual data will not be changed, as it will be immutable; rather, a new version of the data will be created at each transformation step. The functioning of each transformation process can change depending on the system model configuration, and if any such configuration information is required the function will be curried ahead of time. It is also possible that multiple dispatch will be used to handle the same function in different system model contexts. Ideally, the main system model algorithm will be as simple as:
for function in prepared_and_ordered_functions:
data = function(data)
What does this programming paradigm bring to the table? There are several advantages.
First, and most importantly, each transforming function will a small and self-contained section of code, making it easy to understand and test. Functional programming, if done correctly, should have no side-effects, so each function can be independently tested. Ensuring consistent and error-free applications of system models is one of the design goals of Ocelot, and this separation of concerns will help us achieve that goal. An idealized transformation function will look like this:
def transformation_function(data):
new_data = [do_something(dataset) for dataset in data]
The lack of side effects or mutable state can also be a big help when dealing with complicated system modeling options. Those of you who have read through the data quality guidelines know that some system rules can include a complex set of interdependencies. For example, the long-term consequential model uses technology rules to choose the marginal producer of a technosphere flow, but only after excluding certain technologies due to political restrictions. We intend to split this if statement into two separate functions - one of which will remove technologies which are politically limited, and another which will choose the most modern among the remaining technologies. In addition to getting working versions of each system model choice in computer code, this division can really help everyone better understand exactly what, when, and how the different system models function.
In theory, the use of immutable data structures and transforming functions will also make it easy to parallelize the application of the system models. We will test whether there are benefits in the real world - libraries like multiprocessing or scoop still require serialization of data structures, which might negate the speed benefits of distributed processing.
Finally, logging the changes in each transforming step can make it easy to backtrack calculations and locate errors when they occur. This logging is against the strict interpretation of functional programming, as logs are a change in state, or a side effect of a function, but most rules need to be broken every now and then. Logging the data at each step can also make it possible to only run certain parts of the transformation chain, starting from the last known good data.
Changelog
- 15-03-2016: Initial version
- 16-03-2016: Small improvements and clarifications thanks to comments from Guillaume Bourgault